


gena777
Заблокирован
Сразу скажу, материал не мой, но показалось довольно интересным и возникло желание поделиться с теми кто не знает что такое логи и как с ними работать)
Многим будет интересно почитать для общего ознакомления, новичкам вообще необходимо подробно изучить!
Как добыть Логи.
Вариантов добычи логов существует всего два. Либо купить, либо пролить
Естественно, я настоятельно рекомендую покупать логи самостоятельно у селлеров, т.к процесс залива через стиллер/ботнет, довольно тяжелая, кропотливая и расходная операция. Но на всякий случай, рассмотрим кратко оба варианта.
И начну пожалуй со второго.
Изначально, существуют люди (в народе кличут их траферами), распространяющие установки всевозможного софта, среди обычных пользователей. Проще говоря — инсталлы. Чем они хороши? Например тем, что часто программы, в которых будет спрятан наш вирус (стиллер), скачиваются пользователем с официальных маркетов — гугла, эпл стор. Соответственно, высочайший уровень доверия пользователей. Либо с авторитетных порталов и рейтинговых раздач. Так же, преимуществом является их вес — обычно до 30мб. Ну и простота установки для юзера, 1-2 клика и все — конверт произошел. В этом, к слову, инсталлы имеют преимущество перед гемблингом и товаркой (для тех кто всерьез решит заняться трафом) . Установка их занимает минимальное для юзера время. Проги же могут быть разными. Как и различные патчи, читы, торренты (преимущественно для молодежи), так и более коммерцеализированный софт — всевозможные булет журналы, фитнес, приложухи для ведения отчетности, сбора статистических данных, онлайн бухгалтерия, софт для айтишников и даже биржи. Я даже какой-то клинер видел со стилаком. В целом, думаю поняли. Вирус можно спрятать везде. Аудиторию выбираете сами.
Собственно, цены на инсталлеры варьируются, в зависимости от качества и источника инсталлов, а так же страны. Более лучшим вариантом считается USA инсталы. Цены их от 500 до 800 баксов за 1000 инсталлов. ДА-ДА, ребята, уже на этом этапе будьте готовы к большим вложениям, ибо 1000 инстталов чаще всего это минимально возможное количество к покупке у трафера.
Так же, для обхода работы антивирусов юзера, перед процессом пролива происходит криптовка (игра в прятки для нашего подрастающего стилочка). Далее — выбор самого стиллера, которым вы будете проливать купленное вами добро. Наиболее популярный сейчас Аркей. Так же, при покупке стиллера, нужно решить вопрос с абузоустойчивым хостингом, дабы не просрать все вложенные деньги запоротой панелькой. Либо рисковать, юзая бесплатный хост — но в таком случае вы рискуете потерять все. Ну а дальше, происходит процесс залива. В конечном счете из N-го кол-ва инсталлов мы получаем N-ое количество логов. Хорошим отстуком считается 70-80%. Отстук может зависеть от качества инсталов, криптовки, хостинга и т.д. Но если соблюсти все меры осторожности и не жалеть бабок, с 1000 инсталлов проливщик сможет добыть порядка 700-800 логов, из которых примерно треть, после отсева, будет пригодна к продаже и обработке. Хотя, как вы понимаете, цифры тут у всех разные. Кто-то и в ноль умудряется ливать.
Шопимся диффчата
Собственно, учить покупать мат в даркнетах вас не буду. Думаю, сами сможете найти селлеров на различных бордах. Ну или можно спросить у меня, кого-нибудь порекомендую, @acollins в поиске.
Лучше расскажу, на что стоит обращать внимание и как не попасться на говноселлера, толкающего шлак и отработку.
Цены на логи сильно разнятся. Какие-то логи могут стоить от 10 до 40 рублей, какие-то доходят до 20$ за штуку. На цену, в первую очередь, играет вид стиллера, используемого при заливе. Хорошими — считаются стиллеры с широким функционалом. Они имеют кейлогер (функция захвата клавиатуры), благодаря которым вы видите набранные юзером комбинации клавиш, они способны обработать форму логин паролей всех основных браузеров (Хром, Мозила, Опера и т.д.), включают в себя настройки форм-граббера для передачи файлов с пк юзера и утилиты для определения железа. В логе такого стиллера будут акки шопов, кошельки, банки, палка, крипта, сс и т.д. В плохом стиллере — соответственно, будет только примитивный набор логин пароль, а сам лог будет состоять из нескольких аккаунтов к игрулькам, соц.сети, мылу, возможно стиму. Ну и всякий шлак. Наиболее топовым стиллером сейчас считается Аркей.
После покупки, первым делом, смотрим на дату добавления в админ панель. Приемлемым, считается лог не старше 2-3 недель. В идеале, 1-3 дня после залива. Обычно, дата будет отображена в названии самого архивного файла, что пришлет вам селлер.

Обратите внимание, иногда хитрожопые продавцы отработки, переименовывают исходный архив:

Зачем? Чтобы скрыть от вас возраст лога. Но это не беда — можно посмотреть тут.

Настоятельно советую, перед покупкой лога, просить у селлера что-нибудь из отработки или невалида с последнего сделанного залива. Для нормального селлера, у которого в наличии порядка 300-500 логов к продаже, это не вызовет затруднений. Зато у скама, отработавшего лог несколько месяцев назад и желающего втюхать свою жалкую десятку логов с отработки — это вероятно вызовет горение серных слоев атмосферы.
Почему важен возраст лога? Все просто. Куки помогают нам в том случае, если они свежие. Вы же понимаете, что юзер, чьи данные мы используем — как бы не ждет порядочно, пока мы высосем из его кредиток бабки. Конечно нет. О процессе он даже не догадывается и продолжает пользоваться пк как обычно. И если лог старый, у него окажутся более свежие кукисы при заходе на собственный акк, чем у вас. Что вызовет подозрение антифрауд системы. Разумно же? Ну и я уж не говорю о том, что юзер мог прервать сессию и изменить пароль от тех акков, что вы решите хакнуть.
Далее, получив пробник мы удостоверились что лог свежий, что стиллер названный селлером соответствует обещанному (Легко узнаем по структуре папок и файлов, хранившихся в архиве — пример лога Азора).

Теперь проверим лог на предмет источника инсталов. Большинство людей не знает об этом важном моменте. Включая самих селлеров.
Если наш стиллер имеет настройки форм-грабберов в функционале и передает нам файлы и скрины рабочего стола — детально проверяем их на наличие кряков, патчей, активаторов. Если вы их обнаружите, возможно трафер лил с инстал куба (Центр монитизации файлового трафика). Качество таких инсталов оставляет желать лучшего и к работе не рекомендую.
С возрастом, стиллером и инсталами нашего малыша разобрались. Вы купили лог.
Теперь, после покупки, первым делом проверяем содержимое наших файлов и наличие кукисов. Если вы, предположим, приобретаете у селлера лог под выборку (с аркея такой лог стоит в районе 10-20 долларов, в зависимости от запроса), например пейпал, следует сначала проверить файл Password-list.
Читать все от начала до конца не обязательно (хотя и не вредно), благодаря простой комбинации поиска в блокноте (Ctrl+f) вводим запрос "paypal".

Нас автоматом перекинет на нужную строчку в документе. Если запрос отсутствует, смело требуйте от селлера замены. Можно конечно забить на это дело и попытаться подобрать пароль из имеющихся (чаще всего юзеры используют 2-3 постоянных пароля) либо восстановить через мыло — но зачем, если можно попросить замену?). Если с логин+пас все ок — идем в папку, где хранятся наши кукисы. Открываем блокнот, проделывая туже простецкую комбинацию с поиском. Если в логе будут присутствовать строчки искомого запроса, значит кукисы есть. Однако, если увидите значение False, это означает что сервером был получен отрицательный ответ при коннекте. В палку зайти не смогли. Например кх забыл пас и этот неудачный коннект — единственное воспоминание о нас, хранимое в сервере палки. Формально, селлер в праве отказаться от замены, т.к куки есть, но попробуйте договориться. Авось и войдет в положение.
Если все вышеперечисленные условия соблюдены — перейдем наконец к настройке системы.
Система и ip
- ip
Собственно, встречал много разных мнений относительно того, как подстроить айпи и с чего лучше бить. Вероятно, определенно-верного решения здесь нет. Кто-то берет айпи под штат, кто-то под зип. А кто-то бьет с впн под русским айпи (Знаю таких людей лично). Я все же советую ориентироваться на ваш запрос. Если вы решили работать по не самым известным шопам юсы — чистого айпишника без блэков и портов, под штат холдера будет достаточно. Однако советую брать долгоживущие туны, ибо процесс отслеживания ордера может затягивать от нескольких дней до недели и вдобавок родной DNS, избавит нас от сомнительных операций с пабликом. Если вы к примеру, специализируетесь на амазоне, который в свою очередь весьма капризный и чувствительный к регистру с нового айпи адреса, за что сразу накидывает фрод баллы — лучше брать под зип холдера. Да, определенно, амаз может дать вам возможность легко вбить товар на кх, под пикап и рероут, но чаще всего прилетают алерты в течении нескольких часов, на почту кх, а аккаунт холдят и сбрасывают все транзакции. Так же, могут отменить транзу и прислать алерт через 24-36 часов после вбива, когда просто зайдешь проверить статус заказа. Вероятно, такая транзакция подвергалась проверке в ручном режиме. В общем — решайте сами, какой айпи использовать. Главное — чистота. Если VPN — Виндскрайб, ОпенВпн, Ваниш. Если соксы — Фаселс.
Натянули носок/тун/впн — идем чекать наш айпишник. Обычно все советуют проверять на Whoer и Whatleaks. Скажу вам честно, ребята. Уже не первый раз видел инфу относительного того, что бд этих серверов охотно делятся данными о чек-запросах с анти-фрауд конторами и якобы, айпишники чекнутые там? вносятся в какой-то регистр. Достоверной инфы нет, возможно это просто фейк и баллады, а возможно нет, решать вам. Я все же чекаю обычно в сфере, т.к. пользуюсь ей, либо на ip-score. Проверить хороший ваш айпи или плохой, можно так же на векторе (для тех, кто знает). Главное — добейтесь 90-100%ных показателей частоты айпи. Все порты закрыты, блэков нет, время и часовой пояс соответствуют. И удалите к хуям свой TeamViewer, серьезно
Далее, с чего серфить.
Вариантов на самом деле много, но самые ходовые Мозила, Хром, Сфера (только платная).
- Настройка Мозилы. Качаем 54 — 56 английскую версию Лисы.
(Я качал тут, но потом кто-то кричал что якобы ратник нашел. На всякий случай, инспектируйте. Либо качайте с паблика)
Далее, сразу после установки и запуска Мозилы, нужно отключить автообновление. Иначе после 1ой сессии, придется все переделывать.
В адресной строке браузера набрать:
about:config
и нажать Enter
Выдаст аллерт с просьбой быть аккуратным — соглашаемся.
В строке Поиск (чуть ниже адресной строки) наберите app.update. Появится такой список. Ищем
app.update.auto — автоматическое обновление браузера
app.update.enabled — обновление браузера
Переключаем в значение false. Готово. Теперь мозила не обновится без вашего разрешения.
Далее, для работы нам понадобиться поставить 2 плагина.
Так, как лог хранит информацию о браузере, с которого кх логинился на акк, можно подстроиться под него, в юзер агенте. Нужно вам или нет? Решайте сами. Где это не пригодится совсем, где-то поможет не набрать очков фрода, а где-то наоборот наличие юзер агента будет спалено системой и вы привлечете к себе подозрение.
После рестарта Мозилы, открываем import cookies и импортируем файлы с куками нашего логина (Из папки Browser). Каждый грузим отдельно.
Когда загрузили последний — можем начинать работать.
- Хром
Ставим опять же англ. версию хрома. Далее понадобится расширение — Editthiscoockie
Точно так же, как и с мозилой, импортируем поочередно наши куки в браузер.
Почему я не использую эти два варианта, несмотря на простоту и бесплатность. Во-первых, старая версия лисы на пк юзера — для фрауд системы уже подозрительно. Много-ли юзеров в юсе, настолько привередливы к старой версии мозилы, что аж специально, в ручном режиме, отказываются ее обновлять? Это все-равно что всю жизнь с одной бабой прожить, наверное. Бывает и такое конечно, но в освою очередь вызывает любопытство и внимание. Которого нам как раз не нужно.
Второе — это Werbtc. На паблике сложно найти годную информацию о работе этого пидора товарища. Но запомните — Werbtc, один из злейших врагов каржа, на который мы зачастую, даже не обращаем внимание. Нам кажется, что просто отключить (палево) или подменить (палево) значение под айпи сокса/туна будет достаточно. Но это не правда. Запомните, эта херня палит. И настроить ее должным образом, крайне тяжело. В основном, решить вопрос с этой шнягой без должных знаний, можно лишь покупкой годных антиков, вот собственно таких как Сфера, о которой пойдет речь ниже.
По настройке сферы писать особо нужды нет. Качать там ничего не надо, куки грузятся кнопкой в менюшке import cookies, в настройках сессии (жмем правой кнопкой мыши). На сайте есть подробный разбор и настройка в интерактивном режиме. Мне лучше не написать, один хрен.
В общем-то ребята, скажу сразу — Сфера на мой взгляд, лучший и удобнейший браузер для работы с логами (не сочтите за рекламу, но антик сделан на совесть). И да — он платный. Один месяц стандартной версии сферы стоит 100$. Есть более расширенная версия, насколько помню 500$ за пол года. Почему не бесплатный кряк? Кряк говно. Поверьте на слово. Чем хороша сфера? Первое — мультирежимность. Можно иметь 8 сессий с разными логами и легко переключаться между ними, используя под каждый лог собственный айпи и настройки железа. Удобно и быстро. Второе — грамотно настроенная Werbtc, что очень важно. Вы не спалитесь перед каждым 2ым шопом. А так же настроенная WebGL и шрифты, особенно Canvas. Отлаженная работа DNS (многие думают что взять днс с паблика и вбить в настройках адаптера будет достаточно). Так же базовые возможности настройки конфигураций системы под холдера. В вип версии даже режим автоматора (Автопрогрев браузером шопов, не нужно бегать по ссылкам самому, выставил таймер и брауз прогрев шоп за тебя). В общем плюсов очень много и вещь полезная. Для тех, кому налкадно тратить 100 баксов, можно начать с пробной версии. Семь дней за 30$.
Рекомендации по вбивам.
Расписывать, как грамотно работать с каждым шопом и банком в этом мануале я не буду. Каждый шоп, каждый банк, палка и даже разные email домены нужно обрабатывать по своему. Детально, все эти вопросы рассмотрел в этой
Но некоторые рекомендации по работе озвучу.
В первую очередь, начиная работать с логом должно убедиться в порядочности селлера и в том, что продан лог в одни руки. Как это сделать? Достаточно просто. Если акк уже кто-то чекал до вас, вы вероятно заметите следы, оставленные кардером. Например, неоплаченные товары в корзине, либо стаф номиналами от 500-900 баксов (то, что доступно под рероут и пикап), либо гифты (email digital code) — различные ключи к играм, psn и xbox code, т.к многие кардеры пытаются урвать с лога сразу, надеясь на инстант выплаты. Либо, проверив список коннектов с разных айпи адресов, на мыле, нажав на "дополнительная информация", в правом нижнем углу.
Так же с банками, которые требуют обычно для восстановления ssn номер и номер кредитки. Имея на руках лог и всю информацию — вы практически и есть кх, с теми же знаниями, что есть в его собственной голове. Для особо стойких, можно даже соц.сети излазать и добыть инфу там.
Как то раз, я решил развлечься со страничкой какой-то чернокожей сучки. Как оказалось, у нее был снежок любовничек, а муж как водится — олень. Здоровенного вида негрило, видать не раз отбывший и наверняка, с огромной черной битой, о чем снежок мог бы узнать впоследствии. Собственно списался с ним, с левой странички и слил переписку его жены с любовничком, собрав голубков в заранее оговоренное время у них дома, со странички телки. За что Негроид, любезно предоставил мне данные картонки своей шкурятни, в качестве благодарности и лишнего способа наказать неверную, чем я немедленно и с благодарностью воспользовался. Денег там было не много, но свою копейку поимел. Как и + к карме, с диким ором от всей этой истории.
- Это я к чему? Ах да. Заработать тут можно на чем угодно.
Так же, настоятельно не советую вам жадничать и бить кучу всего подряд. Даже если вскрыли кучу шопов, везде есть привязки карт и тд — не жлобтесь. Шопов много, но кредиток и ба меньше. Банки заподозрят кучу подозрительных транзакций и захолдят разом все. В итоге вы останетесь с голой жопой. Помните — вы кх. Вы не бежите в один день покупать 100500 ноутов, гопро, 10 айфонов ХS и лям гифтов для своего игрового магазина. Вы кх — вы копите на сраненький, не самый лучший ноут неделями, а то и месяцами. Привередливо выбираете товар, экономите на доставке и не гонитесь за кучей доп услуг и наворотов. Деньги кх — ваши деньги. А вы знаете точно что такое "экономить"
Так же, работая по юсе, рекомендую узнать предварительно, какой доставкой шоп отправляет стаф на адрес кх. Ибо успешный вбив не гарантирует вам, что ваш пак будет отправлен почтой, пригодной для рероута (Желательно Федя). Или что кх живет в зоне, доступной для пикапа. Зайти то стаф зайдет — но вот доедет ли он до скупа? Еще вопрос. Хотя некоторые ребята умудряются даже ебей юсы вбить на посреда и отправить в ру. Лично таких знаю.
Покупайте логи количеством от 20 штук. Да, возможно это дорого. Но, если вы покупаете по 3-5 акков, вы просто не сможете ничего понять. Если не войдет, в памяти у вас сохранится только отрицательный опыт и вы будете ссать покупать мат дальше. А если войдет — при следующих проебах, будете думать что вам просто один раз повезло. И путем таких колебаний и экономии, в реале вы потратите денег еще больше, а результат будет хуже. Берите приемлемое количество, исходя из которого можно составить более менее адекватные статистические данные. Логи в этом похожи на брут — работать нужно количеством, особенно начинающему. Не бойтесь экспериментировать.
Не отчаивайтесь, если ваши первые попытки провалились. Иногда приходиться перепробовать много раз, прежде чем поймешь, что тебе все это время пихали говномат и ты наконец нашел нормального селлера. Или твой метод вбива не канает.
- Чекайте логи быстро, не давайте им стареть. 1-3 дня, не больше. Кто успел — тот и сьел.
Если не знаете, что делать с акком, помните о том, что его можно продать. Есть БА с балансом, но вы не знаете как его слить? Не губите мат. Напишите на форуме и попробуйте продать. Как минимум окупите покупку лога с лихвой.
Для начинающих советую набивать руку на более старых логах и отработке. Ковыряйте их. Увидите разные способы обхода. Потом будет проще со свежаком. Отдельно изучите способы работы под каждый шоп, с брут аков. Этот опыт будет плюсом.
Заключение
Найдите себе наставника. Хороший ментор — одно из основополагающих факторов достижения успехов, в нашем деле. Мало кто способен копаться сутками в даркнетах, душно добывая инфу. Но всегда есть люди, кто уже прошел ваш путь еще в 2015 году и ему не западло поделиться)
Храни вас Бог, от деклайнов и лохов!
Приветствую всех! Я работаю системным инженером в компании «Онланта». На одном из наших проектов я занимался внедрением и сопровождением Elastic Stack. Мы прошли путь от сбора логов фактически вручную до централизованного, автоматизированного процесса. Вот уже два года мы практически не меняем архитектуру решения и планируем использовать удобный инструмент в других проектах. Нашей историей его внедрения, а также некоторыми сильными и слабыми сторонами делюсь с вами в этом посте.

Источник
В начале 2016 года логи у наших администраторов и разработчиков были, что называется, «на кончиках пальцев», то есть инженер для работы с ними подключался с помощью SSH к хосту, где располагался интересующий его сервис, расчехлял универсальный набор из tail/grep/sed/awk и надеялся, что нужные данные удастся найти именно на этом хосте.

Был у нас и отдельный сервер, куда по NFS монтировались все каталоги с логами со всех серверов, и который иногда надолго задумывался от того, что на нем делали с логами все желающие. Ну а tmux с несколькими панелями c запущенным tail на какие-нибудь активно обновляющиеся логи выглядел для сторонних наблюдателей весьма впечатляюще на большом мониторе и создавал волнительную атмосферу причастности к таинствам продакшена.
Всё это даже работало, но ровно до тех пор, пока не требовалось быстро обработать большой объем данных, а требовалось это чаще всего в моменты, когда в проде уже что-нибудь свалилось.
Иногда на расследование инцидентов требовалось совсем уж неприличное время. Его значительная часть уходила на ручную агрегацию логов, запуск костылей разнообразных скриптов на Bash и Python, ожидание выгрузки логов куда-нибудь для анализа и т.п.
Словом, всё это было весьма медленно, навевало уныние и недвусмысленно намекало на то, что пора бы озаботиться централизованным хранением логов.
Если честно, никакого сложного процесса отбора кандидатов на роль технологического стека, который бы нам это обеспечил, тогда не было: связка ELK на тот момент уже была популярна, обладала хорошей документацией, в интернете по всем компонентам имелось большое количество статей. Решение было незамедлительным: нужно пробовать.

Самую первую инсталляцию стека сделали после просмотра вебинара «Logstash: 0-60 in 60» на трёх виртуальных машинах, на каждой из которых запустили по экземпляру Elasticsearch, Logstash и Kibana.
Дальше мы столкнулись с некоторыми проблемами с доставкой логов с конечных хостов на серверы Logstash. Дело в том, что в то время Filebeat (штатное решение стека для доставки логов из текстовых файлов) гораздо хуже работал с большими и быстро обновляемыми файлами, регулярно протекал в RAM и в нашем случае в целом не справлялся со своей задачей.
К этому добавлялась необходимость найти способ доставлять логи серверов приложений с машин под управлением IBM AIX: основная часть приложений у нас тогда запускалась в WebSphere Application Server, работавшем именно под этой ОС. Filebeat написан на Go, более-менее работоспособного компилятора Go для AIX в 2016 году не существовало, а использовать Logstash в качестве агента для доставки очень не хотелось.
Мы протестировали несколько агентов для доставки логов: Filebeat, logstash-forwarder-java, log-courier, python-beaver и NXLog. От агентов мы ожидали высокой производительности, низкого потребления системных ресурсов, легкой интеграции с Logstash и возможности выполнять базовые манипуляции с данными силами агента (например, сборку многострочных событий).
Про сборку многострочных (multiline) событий стоит сказать отдельно. Эффективно ее можно выполнять только на стороне агента, который читает конкретный файл. Несмотря на то, что Logstash когда-то имел multiline-фильтр, а сейчас обладает multiline-кодеком, все наши попытки совместить балансировку событий по нескольким серверам Logstash с обработкой multiline на них же провалились. Такая конфигурация делает эффективную балансировку событий практически невозможной, поэтому для нас чуть ли не самым важным фактором при выборе агентов была поддержка multiline.
Победители распределились так: log-courier для машин с Linux, NXLog для машин с AIX. С такой конфигурацией мы и прожили почти год без особых проблем: логи доставлялись, агенты не падали (ну почти), все были довольны.
В октябре 2016 года была выпущена пятая версия компонентов Elastic Stack, в том числе и Beats 5.0. В этой версии над всеми агентами Beats была проделана большая работа, и мы смогли заменить log-courier (у которого к тому времени обнаружились свои проблемы) на Filebeat, который мы и используем до сих пор.
При переходе на версию 5.0 мы стали собирать не только логи, но и некоторые метрики: Packetbeat у нас начал кое-где использоваться как альтернатива записи логов HTTP-запросов в файлы, а Metricbeat собирал системные метрики и метрики некоторых сервисов.
К этому моменту работа наших инженеров с логами стала гораздо проще: теперь не нужно было знать, на какой сервер идти, чтобы посмотреть интересующий тебя лог, обмен найденной информацией упростился до простой передачи ссылки на Kibana в чатах или почте, а отчеты, которые раньше строились за несколько часов, стали создаваться за несколько секунд. Нельзя сказать, что это был просто вопрос комфорта: изменения мы заметили и в качестве нашей работы, в количестве и качестве закрытых задач, в скорости реагирования на проблемы на наших стендах.
В какой-то момент мы начали использовать утилиту ElastAlert от компании Yelp для рассылки алертов инженерам. А потом подумали: почему бы не интегрировать ее с нашим Zabbix, чтобы все алерты имели стандартный формат и отправлялись централизованно? Решение нашлось довольно быстро: ElastAlert позволяет вместо отправки, собственно, оповещений выполнять любые команды, что мы и использовали.
Сейчас наши правила ElastAlert при срабатывании выполняют bash-скрипт на несколько строк, которому в аргументах передают необходимые данные из события, вызвавшего срабатывание правила, а из скрипта, в свою очередь, вызывается zabbix_sender, который и отправляет данные в Zabbix для нужного узла.
Так как вся информация о том, кто и где сгенерировал событие, в Elasticsearch всегда есть, никаких сложностей с интеграцией не возникло. Например, у нас и раньше существовал механизм автоматического обнаружения серверов приложений WAS, а в событиях, которые они генерируют, всегда записывается имя сервера, кластера, ячейки и т.д. Это позволило нам использовать в правилах ElastAlert опцию query_key, чтобы условия правил обрабатывались для каждого сервера отдельно. Скрипту с zabbix_sender затем уходят точные «координаты» сервера и данные отправляются в Zabbix для соответствующего узла.
Еще одно решение, которое нам очень нравится и которое стало возможным благодаря централизованному сбору логов, – это скрипт для автоматического заведения тасков в JIRA: раз в сутки он выгребает все ошибки из логов и, если по ним еще нет тасков, заводит их. При этом из разных индексов по уникальному ID запроса в таск подтягивается вся информация, которая может пригодиться при расследовании. В результате получается эдакая стандартная заготовка с необходимым минимумом информации, которую потом инженеры могут дополнять при необходимости.
Разумеется, перед нами вставал вопрос мониторинга самого стека. Частично это реализовано с помощью Zabbix, частично с помощью все того же ElastAlert, а основные performance-метрики по Elasticsearch, Logstash и Kibana мы получаем с помощью штатного мониторинга, встроенного в стек (компонент Monitoring в X-Pack). Также на самих серверах с сервисами стека у нас установлена netdata от Firehol. Она бывает полезна, когда нужно посмотреть, что происходит с конкретной нодой прямо сейчас, в реальном времени и с высоким разрешением.
Когда-то в ней была немного поломан модуль для мониторинга Elasticsearch, мы это обнаружили, починили, добавили всяких полезных метрик и сделали пулл-реквест. Так что теперь netdata умеет мониторить последние версии Elasticsearch, включая базовые метрики JVM, показатели производительности индексации, поиска, статистику по логу транзакций, сегментам индексов и так далее. Netdata нам нравится, и нам приятно, что мы смогли сделать небольшой вклад в неё.
Сегодня, спустя почти три года, наш Elastic Stack выглядит примерно таким образом:
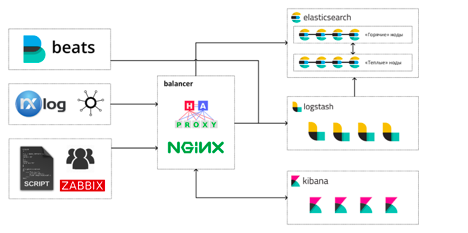
Инженеры работают со стеком тремя основными способами:
- просмотр и анализ логов и метрик в Kibana;
- дашборды в Grafana и Kibana;
- прямые запросы к Elasticsearch с использованием SQL или встроенного query DSL.
Суммарно на всё это выделены такие ресурсы: 146 CPU, 484GB RAM, под хранилище данных Elasticsearch выделено 17TB.
Всего у нас в составе Elastic Stack сейчас трудятся 13 виртуальных машин: 4 машины под «горячие» ноды Elasticsearch, 4 – под «тёплые», 4 машины с Logstash и одна машина-балансировщик. На каждой горячей ноде Elasticsearch запущено по экземпляру Kibana. Так сложилось с самого начала, и пока что у нас не было необходимости перемещать Kibana на отдельные машины.
А вот решение вынести Logstash на отдельные машины оказалось, наверное, одним из самых правильных и результативных за время эксплуатации стека: высокая конкуренция за процессорное время между JVM Elasticsearch и Logstash приводила к не очень приятным спецэффектам во время всплесков нагрузки. Больше всех страдали сборщики мусора.

Мы храним в кластере данные за последние 30 дней: сейчас это около 12 млрд. событий. В сутки «горячие» ноды записывают на диск 400-500ГБ новых данных с максимальной степенью сжатия (включая данные шардов-реплик). Наш кластер Elasticsearch имеет архитектуру hot/warm, но перешли мы на неё сравнительно недавно, поэтому на «тёплых» нодах пока что хранится меньше данных, чем на «горячих».
Наша типичная нагрузка для рабочего времени:
- индексация – в среднем 13000 rps с пиками до 30000 (без учета индексации в шарды-реплики);
- поиск – 5200 rps.
Мы стараемся поддерживать запас по использованию CPU в 40-50% на горячих нодах Elasticsearch, чтобы без проблем переживать внезапные всплески количества индексируемых событий и тяжелые запросы от Kibana/Grafana или внешних систем мониторинга. Около 50% RAM на хостах с нодами Elasticsearch всегда доступно для page cache и off-heap нужд JVM.
За время, прошедшее с запуска первого кластера, мы успели для себя определить некоторые положительные и отрицательные стороны Elastic Stack как средства агрегации логов и поисково-аналитической платформы.
Что нам особенно нравится в стеке:
- Единая экосистема хорошо интегрированных друг с другом продуктов, в которой есть практически всё необходимое. Beats когда-то были не очень хороши, но сейчас претензий к ним у нас никаких нет.
- Logstash, при всей его монструозности, очень гибкий и мощный препроцессор и позволяет делать с сырыми данными очень многое (а если чего-то не позволяет, всегда можно написать сниппет на Ruby).
- Elasticsearch с плагинами (а с недавних пор и «из коробки») поддерживает SQL в качестве языка запросов, что упрощает его интеграцию с другим софтом и людьми, которым SQL как язык запросов ближе.
- Качественная документация, которая позволяет быстро вводить новых сотрудников на проекте в курс дела. Эксплуатация стека, таким образом, не становится делом одного человека, обладающего каким-то специфическим опытом и «тайными знаниями».
- Отсутствие необходимости заранее знать о структуре получаемых данных многое для начала их сбора: можно начать агрегировать события как есть, а затем, по мере появления понимания, какую полезную информацию можно из них извлечь, менять подход к их обработке, не теряя «обратную совместимость». В стеке для этого есть много удобных инструментов: алиасы полей в индексах, scripted fields и т. д.

Что нам не нравится:
- Компоненты X-Pack распространяются только по модели подписок и никак иначе: если из Gold, к примеру, только поддержка RBAC или PDF-отчетов, то платить придется за всё, что в Gold есть. Это особенно расстраивает, когда, например, из Platinum нужен только Graph, а в довесок приобрести предлагается Machine Learning и ещё пачку другой функциональности, которая вам, может быть, не очень-то и нужна. Наши попытки около года назад пообщаться с отделом продаж Elastic насчёт лицензирования отдельных компонентов X-Pack ни к чему не привели, но, возможно, с тех пор что-то изменилось.
- Довольно частые релизы, в которых каким-нибудь образом (каждый раз новым) ломают обратную совместимость. Приходится очень внимательно читать чейнжлог и готовиться к обновлениям заранее. Каждый раз нужно выбирать: остаться на старой версии, которая работает стабильно или попробовать обновиться ради новых фич и прироста производительности.
В целом же мы очень довольны нашим выбором, сделанным в 2016 году, и планируем переносить опыт эксплуатации Elastic Stack на другие наши проекты: инструменты, предоставляемые стеком, очень плотно вошли в наш рабочий процесс и отказаться от них сейчас было бы очень сложно.

Решая различные компьютерные задачи, можно не раз столкнуться с таким понятием как лог (с англ. log). Лог какой-то программы. Давайте попробуем разобраться что это такое и для чего это нужно.
Log (с англ. журнал). У большинства программ, которые установлены на вашем компьютере, есть этот самый журнал.
Журнал — это специальный текстовый файл, в который программа может вносить какие-то записи.
Т.е. это такой же обычный файл, который мы с вами можем создать на компьютере. Таким же образом программа работая на компьютере, может создать этот файл и вносить туда программным образом какие-то текстовые пометки.
Зачем же программе вести какие-то записи, какой-то журнал?
Дело в том, что если мы с вами будем следить за человеком, который работает на компьютере, мы можем сказать, что этот человек делал в конкретный момент времени, какие программы он запускал, какие ошибки он совершал при работе на компьютере и.т.д.
Но, если мы говорим о компьютерной программе, здесь все не так ясно. Все действия, которые производит программа, они скрыты от взгляда обычного пользователя. Они обычно происходят с такой большой скоростью событий, что человеческий глаз просто не успеет за все этим уследить.
Для того, чтобы отслеживать состояние какой-то программы. Что делала программа в какой-то конкретный момент времени, какие при этом возникали ошибки, кто с этой программой взаимодействовал и др. вопросы. Все события, которые происходили с этой программой, эта программа может записывать в специальный журнал, так называемый лог-файл.
Лог файлов для программы может быть несколько. В зависимости от назначения может быть так называемый access_log — это журнал, где фиксируются все взаимодействия пользователей с этой программой, что они делали и.т.д.
В лог файле может множество записей. Каждая текстовая строка — это одно взаимодействие с программой.
В каждой записи содержится информация о том, что происходило с программой и когда это происходило.
Также можно часто встретить так называемый error_log — это лог тех ошибок, которые возникали при работе с программой. В этом логе можно увидеть код ошибки, которая произошла в программе, когда эта ошибка произошла, каким пользователем операционной системы эта ошибка была вызвана и.т.д.
Давайте подведем итог, что такое лог и зачем он нужен. Это текстовый файл, в который программа записывает какие-то события, которые с ней происходят. Благодаря этим событиям мы можем получить какую-то дополнительную информацию, что происходило с этой программой в какой-то определенный момент времени, получить отладочную информацию, чтобы легче устранить какую-то ошибку.
В общем лог — это бесценная информация, который может воспользоваться любой пользователь компьютера, чтобы узнать что и в какой момент времени происходило с программой.
Лог — это первоисточник, в который нужно заглядывать если ваша программа работает с каким-то ошибками и не так, как нужно.
Надеюсь, что стало понятнее что такое лог-файл и зачем он нужен и вы теперь будете использовать этот журнал в своей работе.